DIGIT: goal-directed data interaction infrastructure
Topic: scientific datasets remain underused because the interface around them is fragmented.
Core idea: DIGIT replaces raw-data access requests with goal-directed, natural-language interaction.
What changes: researchers ask whether a dataset can answer a question; DIGIT translates that intent, runs approved analysis inside the protected environment, and returns only bounded outputs.
Why it matters: DIGIT can range from a directly queryable tool to an autonomous supervisor that keeps experiments grounded in data and on track, while accumulating a reusable map of scientific intuition linking experiments to what datasets can and cannot answer.
GitHub
Research Note - March 23, 2026
DIGIT is a proposal for a governed interface between researchers and protected datasets. The core claim is simple: many data bottlenecks are really interface bottlenecks, and a bounded question-answer layer may unlock scientific utility without exposing raw data.
The Problem
In biomedicine, many of the most valuable datasets remain scientifically idle inside hospitals, pharma, and research institutions. The limiting factor is often not that the data do not exist. It is that the path from a research question to a usable answer is blocked by privacy, governance, access, and tooling friction.
That creates a bad tradeoff. Researchers need datasets that are accessible, usable, reliable, and fast enough to support real scientific work. Dataset owners need guarantees that use can happen safely, compliantly, and without giving up control. Most current systems solve one side by weakening the other.
Main thesis: stop treating every scientific question as a request for raw-data access. Treat it as a request for bounded evidence.
Origin
Coming from a Biomedical and Software Engineering background and working on high-throughput data pipelines in research computing, I kept seeing the same pattern: teams were building policies and patches around the bottleneck instead of redesigning the interface that creates it.
DIGIT emerged from that observation. The goal was not just safer access to data, but a better infrastructure layer for scientific progress.
Why Current Approaches Stall
- Data-sharing agreements preserve legal friction. They may unlock access eventually, but they add coordination overhead before any science can start.
- Secure enclaves relocate friction. Access becomes possible, but the burden moves into approvals, onboarding, and environment-specific technical work.
- Synthetic data often weakens exactly the signal science cares about. Rare effects, subgroup behavior, and weak correlations are often where fidelity matters most.
- Rigid APIs assume governance can be fully specified in advance. In practice, safe use depends on purpose, context, and the pattern of questioning.
Most existing approaches ask who should get access to data. DIGIT asks whether the data can answer the scientific question safely.
The Proposal
DIGIT, short for Dataset Intent-Gated Inference Tool, is a governed research interface I built and tested as a proof of concept. It sits between a researcher and a protected dataset.
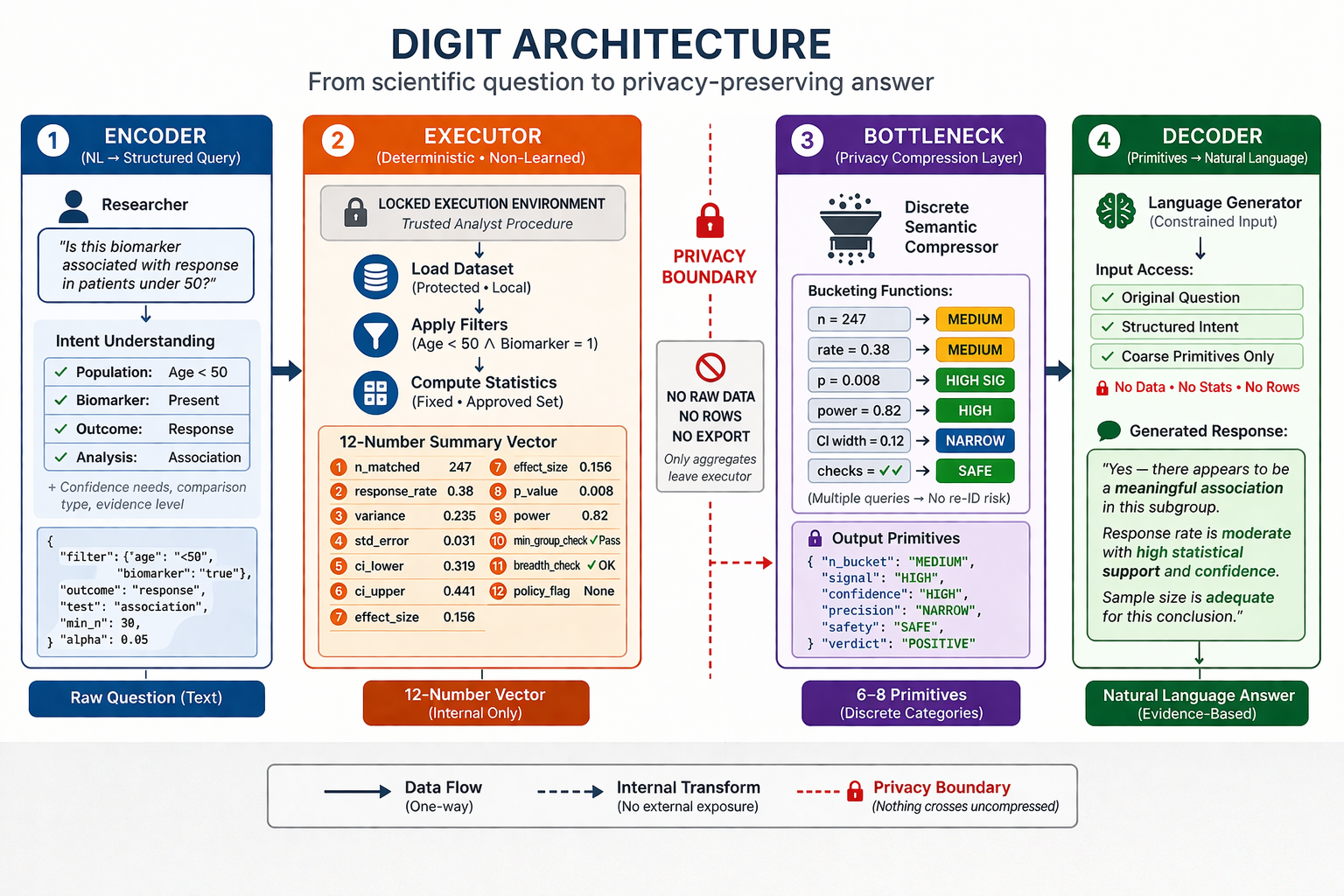
Instead of asking for raw access, a researcher asks whether the dataset can answer a specific question. DIGIT handles the translation, execution, filtering, and response generation in between. DIGIT can operate at different levels of autonomy, from a directly queryable tool to one that helps keep an experiment on track with minimal supervision.
Question -> intent -> approved query -> bounded statistics -> coarse answer
How DIGIT Works
Step 1
An encoder translates a plain-language question into structured scientific intent: subgroup, outcome, comparison, and evidence target.
Step 2
The intent is routed to a predefined set of approved query types that can run inside the protected environment.
Step 3
An executor computes only bounded aggregate statistics over the relevant records, without exposing raw data.
Step 4
A bottleneck compresses the result into coarse outputs such as yes, no, maybe, high confidence, low confidence, or blocked, and a decoder turns that into a readable answer.
Why The Bottleneck Matters
The bottleneck is the main architectural move. In most systems, privacy is enforced mainly by policy. In DIGIT, part of that control is pushed into the interface itself.
- Raw records stay inside the protected environment.
- Allowed query families are predefined and governable.
- Outputs are intentionally coarse rather than fully analytical.
- Exposure can be tuned at both the query level and the answer level.
The aim is not to claim zero privacy risk. It is to make the remaining risk bounded, testable, and tunable.
What The Interface Leaves Behind
If every question must pass through a structured, governed representation, then the interaction itself becomes useful. DIGIT can preserve the trail from scientific intent to bounded evidence to final answer.
At scale, those trails could accumulate into a map of what datasets can answer, where evidence repeatedly converges, and where important questions keep failing. In that sense, the map is not an extra feature. It is a structural consequence of the interface.
Early Results
| Test | What was measured | Current read |
|---|---|---|
| Privacy | Membership inference drops from AUROC 1.0 on raw data to about 0.55-0.59, close to the best differential privacy baseline of 0.53. | Promising, but differencing attacks still need stronger stress-testing. |
| Utility | The best DIGIT variant scored 0.687 on the first utility benchmark versus 0.673 for the best differential privacy baseline. | Useful guidance appears preservable under the bottleneck. |
| Infrastructure | If deployed broadly, the system should accumulate a record of which questions datasets can answer and where evidence repeatedly fails. | This is still a forward-looking architectural claim, not yet a validated large-scale result. |
So far, DIGIT appears less like a replacement for formal privacy methods and more like an interface layer for balancing privacy and scientific utility in a controlled, testable way. The preliminary results reported here are based on experiments using TCGA, PRISM, and NIST datasets.
Why Now
The bottleneck itself is not new. What is new is who now needs to cross it. Scientific agents are arriving faster than the infrastructure needed to let them work safely on protected data.
For a human researcher, months of access friction are costly. For an agent running continuous hypothesis loops across institution-bound datasets, that same friction is a hard stop. And because many of the most valuable biomedical datasets are historical and local, they cannot simply be recreated elsewhere.
Why now: the tools capable of exploiting protected datasets are arriving faster than the interfaces needed to use them safely.
What Would Falsify DIGIT
- If repeated querying can recover membership or sensitive attributes too reliably, the privacy claim fails.
- If the bounded output destroys too much signal to guide real scientific decisions, the utility claim fails.
- If the interaction trace does not accumulate into anything scientifically useful at scale, the infrastructure claim weakens substantially.
Status
Current position
DIGIT is best read as a proof-of-concept for a new scientific interface layer, not as a finished product. The main claim is architectural: useful interaction and controlled exposure do not have to be opposites.